About YouTube Data
Datasets that we use for this project are about YouTube Videos. The data is collected by a webcrawler using YouTube APIs and is publically available on a web page at Simon Fraser University's website. The raw data contains the features described below.
| Video ID | Uploader | Age | Category | Length | Views | Rate | Ratings | Comments | Related IDs |
|---|---|---|---|---|---|---|---|---|---|
| bRPeEVpHiI8 | ufc | 744 | Sports | 154 | 331333 | 3.32 | 1284 | 103 | "bRPeEVpHiI8,D7-oJH4TR88,etc" |
Some of them (e.g. Video ID) will be self-explanatory, but several will not be. Age refers to how old the video (not the uploader) is. The difference between Rate and Ratings is that Ratings represents how many times the video has been rated while Rate is the actual rating value (number of stars); similarly, Comments represents how many comments have been posted rather than what people have commented.
More than 100 datasets are available on the original site. Since the duration time of the webcrawler is different, each dataset has a different size. A small one is, for example, less than 100KB, but a large one can be more than 10MB. The oldest dataset was created on February 2007, and the newest on September 2008. We are using a dataset (0.txt) created on March 2, 2007. In order to visualize it, we preprocessed the data: Views and Rate (aka Stars) changed numerical values to categorical values. Some values of Category are also changed. The details are as follows:
Views
< 10k: All videos views of which are less than 10,000
< 50k: Less than 50,000
< 100k: Less than 100,000
≥ 100k: Equal or more than 100,000
Stars
1: Rates between 0 and 0.99..
2: between 1 and 1.99..
3: between 2 and 2.99..
4: between 3 and 3.99..
5: between 4 and 5
Category
'Others' contains the following categories:
1. Howto & DIY
2. Pets & Animals
3. Autos & Vehicles
4. Gadgets & Games
5. Travel & Places
Findings
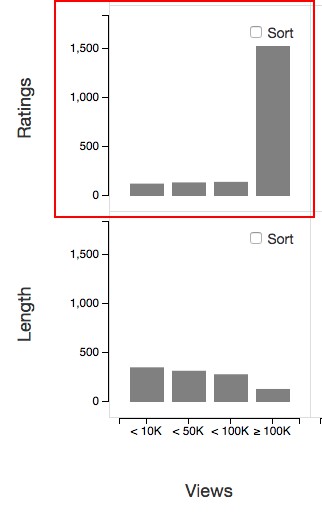
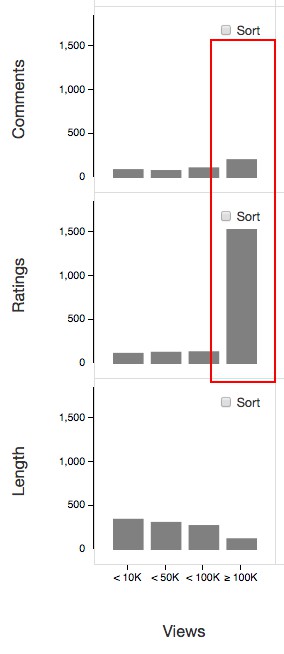
What we learned from the dataset using our visualization and consider to be of interest are the following three points:- First, people rate videos more often as the number of video views increases. This is not surprising, but if the number of views exceeds 100,000, the number of ratings suddenly increases significantly.
- Second, by contrast, this is not true for the number of comments. The number of both comments and ratings increases monotonically as the number of views increases; yet, the number of comments does not increase as much as the ratings when the views exceed 100,000. This may imply that people tend to rate only, rather than making a comment, when they watch popular videos.
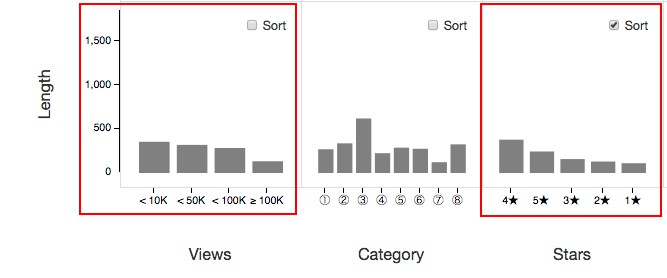
- Finally, ratings tend to be higher as the length of the video increases. In other words, people seem to prefer longer videos over shorter ones in general. Meanwhile, the length tends to decrease as videos are viewed repeatedly. Our thinking about this is because shorter videos are easier to view and to share.